这是友松实验室高考志愿 AI 测评基准(Gaokao AI benchmark)的第三方评估报告。这份报告不是给某个 AI 产品做结论性背书,而是建立一套可复现、可扩展的高考志愿 AI 评估框架,并以千问高考志愿填报Agent作为本轮案例对象,观察它在四类真实任务中的表现:高考志愿基本事实与规则、模拟志愿填报、开放式咨询、志愿表推荐报告。选择千问作为案例,是因为其背后团队已有 8 年高考服务经验,产品也已经进入真实高考服务场景,适合用来检验这套基准能否评估一个具体的高考志愿 AI 产品。
友松实验室的基本判断是:高考志愿 AI 不应只是“会聊天”,而应能帮助人做决策。 高考志愿填报不是一道问答题,而是一整套决策流程:查政策、核专业、估风险、排顺序、和家人讨论取舍。一个好的 AI 产品,必须能接入权威数据,说明判断依据,主动识别硬约束和风险,并把复杂信息整理成可比较、可复核、能拿来讨论的方案。对应地,一个好的测评基准,也不应只问 AI 能不能答出漂亮文字,而要检验它能不能在真实填报流程中帮助学生、家长和咨询师更快获得可靠信息,更准确地判断风险,更稳妥地做关键教育决策。
总结
背景
这份报告要回答一个具体问题:高考志愿 AI 到底能在真实填报流程中帮上什么忙,又有哪些地方不能替代人。为此,友松实验室把高考志愿咨询拆成四类任务来评估:规则事实、模拟志愿填报、开放式咨询问答、完整志愿报告。AI 侧案例对象为千问高考志愿填报Agent;人类基准为 53 名有经验的高考志愿咨询师,平均从业约 4.6 年。数据、样本和评分方法在后文的“数据、样本与方法”中单独说明。
核心结论
千问高考志愿填报Agent多项表现达到有经验的人类咨询师水平,在三方面呈现出优势:
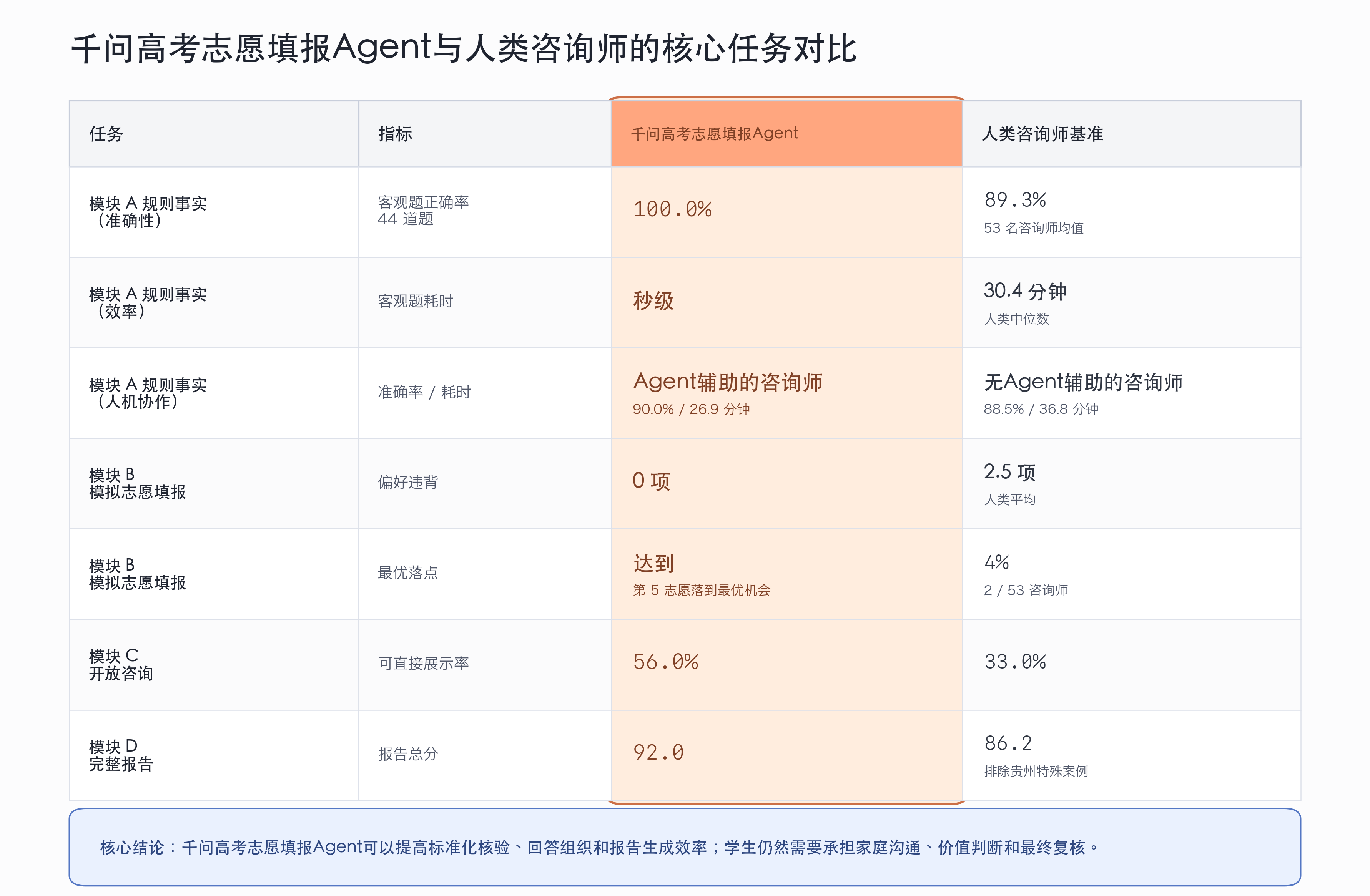
第一,规则事实判断的稳定性。44道客观题千问满分,53名人类咨询师平均正确率89.3%。千问的价值是把查章程、核目录、确认政策边界这类标准化工作,从“依赖个人经验和状态”变成可预期的稳定输出。
第二,偏好执行更精确。模拟志愿填报中,千问0项偏好违背、录取到最优方案;人类咨询师平均2.5个偏好违背,仅4%达到最优落点。
第三,结构化表达与效率更优。专家盲评可直接展示率千问56%、人类33%,100场两两对决赢58场。人机协作实验中Agent辅助耗时减少约27%。
但人类咨询师的不可替代性同样清楚:
在收入预期、就业判断等需要谨慎校准的话题上,更能基于个体实际给予建议;
在亲子协商、价值取舍等场景中,结构完整不等于可以直接交付给一个正在经历家庭冲突的学生。
但无论AI报告还是咨询师方案,都不该直接当成最终志愿表。考生和家庭需要结合自己的风险承受力和个人偏好做最后一轮确认。志愿填报本来就是“信息越透明、决策越安心”的过程——AI让信息透明,咨询师让决策安心,两者叠在一起,才算能更好支持志愿填报。
具体如下:
第一,模块 A 显示,AI 在规则事实任务上最稳定,也最容易直接帮助人类决策。 44 道客观题中,千问全部答对;53 名人类咨询师平均答对 39.28 题,正确率为 89.3%,其中也有 3 人拿到满分。人类咨询师完成 44 道题的中位耗时为 30.4 分钟,千问输出同类内容几乎是秒级;在人机协作实验中,Agent辅助的咨询师平均耗时比无Agent辅助的咨询师少约 27%,正确率从 88.5% 提高到 90.0%。这个结果不是说人类咨询师做不到,而是说明高考志愿里有一类工作适合交给系统反复核验:招生章程、专业目录、院校实体、政策边界和硬性条件。对学生、家长和咨询师来说,Agent 的价值是先把容易记错、漏查、误判的规则事实校正掉,让后面的专业选择、城市取舍和家庭讨论建立在更可靠的底座上。
第二,模块 B 显示,AI 在完整志愿方案中的偏好执行、排序和风险校准更稳定。 在模拟志愿填报回测中,千问方案包含 6 个可录取志愿、0 项显性偏好违背,并最终录取到事后评估的最优方案。人类咨询师平均有 5.3 个可录取志愿,但同时伴随 2.5 个偏好违背项,只有 4% 的方案达到同样的最优落点。人类咨询师的平均表现并不差,但个体差异很大,容易受到经验惯性、前一年分数锚定和个人风险偏好的影响。千问的价值在于把分数、偏好、风险和排序放进可复核的框架里,帮助校正人类决策中常见的偏差。
第三,模块 C 显示,千问在开放式咨询中的优势主要是结构化表达,而不是事实核验已经完成。 模块 C 设计了 10 道开放式咨询题,由 10 位专家在匿名条件下评分,并对每道题的千问回答和人类咨询师回答做两两比较。由此形成的 100 场两两对决中,千问赢下 58 场;可直接展示率为 56.0%,高于人类咨询师回答的 33.0%。专家更常认为千问回答可以直接给学生或家长看,原因不是答案更长,而是它更容易把复杂问题组织成可读、可执行的回答:先拆条件,再讲风险,再给选择路径和下一步行动。但开放咨询回答仍然不能替代正式填报前的事实核验;真正落到志愿表时,招生章程、最新招生计划、录取数据和省份规则仍需要逐项复核。
第四,模块 D 显示,完整志愿报告不仅要“有观点”,还要能看、能填、能复核。 模块 D 包含湖南、辽宁、贵州三个完整报告案例。其中湖南和辽宁双方都提交了完整志愿表,可以直接比较总分:千问报告平均为 92.0,人类咨询师报告平均为 86.2。贵州的情况不同:千问提交了带志愿表的完整报告,人类咨询师报告主要是方向性分析,没有给出可直接填报的完整志愿表,因此贵州不进入上述均值,而是单独呈现。单看贵州,千问总分为 92.5,与湖南 93.0、辽宁 91.1 接近;人类报告虽然总分受缺少志愿表影响,但报告解释部分为 55.3/65,与湖南人类报告 54.3 接近,也高于辽宁人类报告 48.9。也就是说,贵州人类报告并非没有咨询价值,主要问题是没有把方向性分析落成可填报、可排序、可复核的完整志愿表。
整体来看,千问高考志愿填报Agent更像一个决策支持系统,而不是直接替代咨询师的“答案机”。 它的强项是降低信息检索、初筛排序、规则核验和方案生成的成本,让学生和家庭更早拿到一份可讨论、可追问、可复核的底稿。它的边界也同样清楚:家庭沟通、价值冲突、责任边界和最终把关仍然需要学生、家长和专业咨询者共同完成。比较合理的使用方式,是先用 AI 打好信息和方案底稿,再由人来处理风险承受、家庭偏好、长期规划和最终确认。
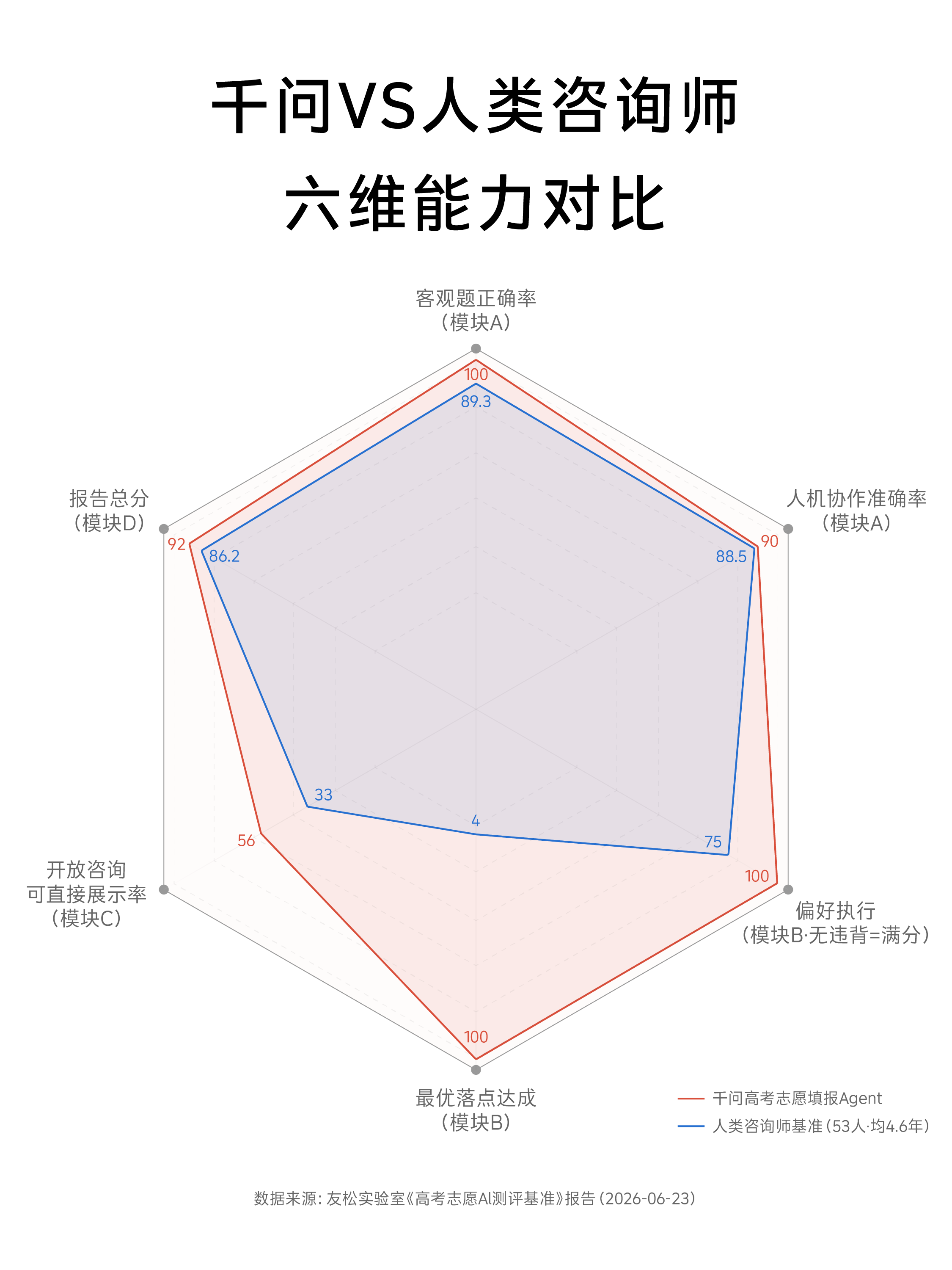
下图把四类任务放在同一页中比较:规则事实看正确率和耗时,模拟志愿填报看偏好违背和最终落点,开放式咨询看回答能否直接给学生或家长阅读,完整志愿报告看同行评分。从这些指标看,千问在规则核验、偏好执行和最优落点上优势更明显;在开放咨询和完整报告中,优势主要来自结构化表达,但仍需要人工参与价值判断和最终复核。
下方雷达图进一步把可转为百分比或百分制的核心指标整理为六个维度。它不把所有结果压成一个总分,而是把不同任务的强弱分开呈现:哪些环节更适合 AI,哪些环节仍需要人参与。